

Our whitepaper about the systemic risk of risk modelling is now out. The topic is how the risk modelling process can make things worse – and ways of improving things. Cognitive bias meets model risk and social epistemology.
The basic story is that in insurance (and many other domains) people use statistical models to estimate risk, and then use these estimates plus human insight to come up with prices and decisions. It is well known (at least in insurance) that there is a measure of model risk due to the models not being perfect images of reality; ideally the users will take this into account. However, in reality (1) people tend to be swayed by models, (2) they suffer from various individual and collective cognitive biases making their model usage imperfect and correlates their errors, (3) the markets for models, industrial competition and regulation leads to fewer models being used than there could be. Together this creates a systemic risk: everybody makes correlated mistakes and decisions, which means that when a bad surprise happens – a big exogenous shock like a natural disaster or a burst of hyperinflation, or some endogenous trouble like a reinsurance spiral or financial bubble – the joint risk of a large chunk of the industry failing is much higher than it would have been if everybody had had independent, uncorrelated models. Cue bailouts or skyscrapers for sale.
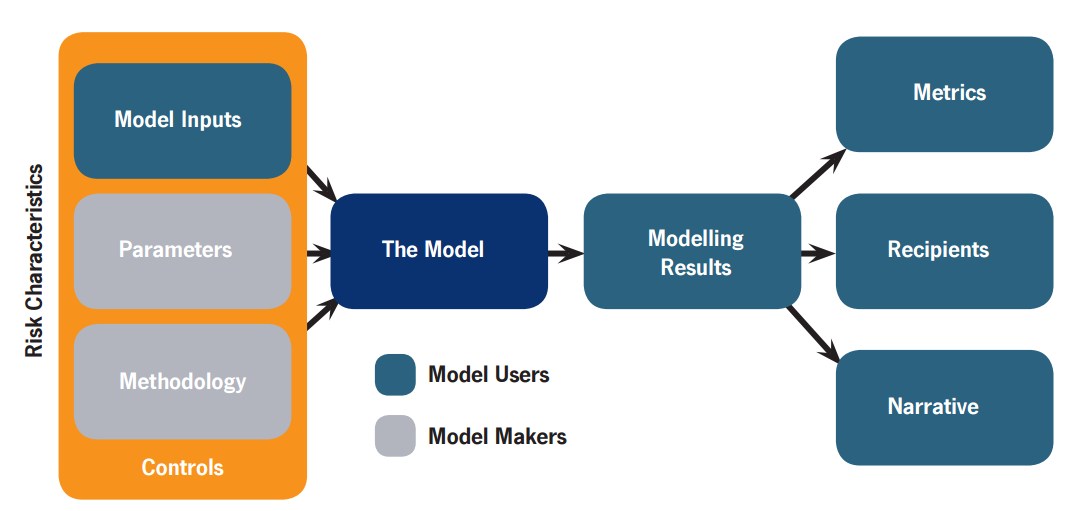 Note that this is a generic problem. Insurance is just unusually self-aware about its limitations (a side effect of convincing everybody else that Bad Things Happen, not to mention seeing the rest of the financial industry running into major trouble). When we use models the model itself (the statistics and software) is just one part: the data fed into the model, the processes of building and tuning the model, how people use it in their everyday work, how the output leads to decisions, and how the eventual outcomes become feedback to the people involved – all of these factors are important parts in making model use useful. If there is no or too slow feedback people will not learn what behaviours are correct or not. If there are weak incentives to check errors of one type, but strong incentives for other errors, expect the system to become biased towards one side. It applies to climate models and military war-games too.
Note that this is a generic problem. Insurance is just unusually self-aware about its limitations (a side effect of convincing everybody else that Bad Things Happen, not to mention seeing the rest of the financial industry running into major trouble). When we use models the model itself (the statistics and software) is just one part: the data fed into the model, the processes of building and tuning the model, how people use it in their everyday work, how the output leads to decisions, and how the eventual outcomes become feedback to the people involved – all of these factors are important parts in making model use useful. If there is no or too slow feedback people will not learn what behaviours are correct or not. If there are weak incentives to check errors of one type, but strong incentives for other errors, expect the system to become biased towards one side. It applies to climate models and military war-games too.
The key thing is to recognize that model usefulness is not something that is directly apparent: it requires a fair bit of expertise to evaluate, and that expertise is also not trivial to recognize or gain. We often compare models to other models rather than reality, and a successful career in predicting risk may actually be nothing more than good luck in avoiding rare but disastrous events.
What can we do about it? We suggest a scorecard as a first step: comparing oneself to some ideal modelling process is a good way of noticing where one could find room for improvement. The score does not matter as much as digging into one’s processes and seeing whether they have cruft that needs to be fixed – whether it is following standards mindlessly, employees not speaking up, basing decisions on single models rather than more broad views of risk, or having regulators push one into the same direction as everybody else. Fixing it may of course be tricky: just telling people to be less biased or to do extra error checking will not work, it has to be integrated into the organisation. But recognizing that there may be a problem and getting people on board is a great start.
In the end, systemic risk is everybody’s problem.
- This article was originally published on Anders Sandberg's blog ANDART II
This opinion piece reflects the views of the author, and does not necessarily reflect the position of the Oxford Martin School or the University of Oxford. Any errors or omissions are those of the author.